-
쿠버네티스 | 쿠버네티스 아키텍처kubernetes 2021. 5. 30. 01:49
쿠버네티스를 정리함에 있어서 기본적으로 쿠버네티스가 내부적으로 어떻게 동작하는지에 대해서 알아보기 위해 정리하는 시간을 가지게 되었습니다.
쿠버네티스 구성
쿠버네티스는 다음과 같이 크게 Master와 Node 2가지로 구성됩니다.
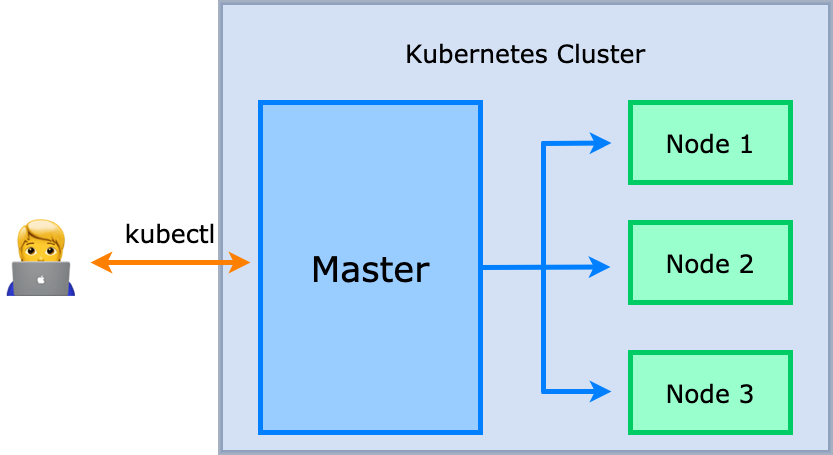
위의 그림처럼 사용자는 kubectl이라는 것을 이용하여 쿠버네티스 클러스터와 통신을 하게 됩니다.
클러스터 내의 Master는 쿠버네티스의 설정 환경을 저장하고 전체 클러스터를 관리하는 역할을 맡고 있고, 각 Node들에서는 쿠버네티스 위에서 동작하는 워크로드들이 실행되게 됩니다.
그렇다면 좀 더 자세하게 Master에서는 어떻게 해서 위에서 설명한 역할들을 수행하고 있고 마찬가지로 Node에서는 어떻게 워크로드들이 실행되게 되는지 알아보겠습니다.
쿠버네티스 기본 개념
Master와 Node에 대해서 알기 전에 쿠버네티스의 기본 개념에 대해서 알고 넘어가도록 하겠습니다.
쿠버네티스의 기본 개념은 desired state(원하는 상태)라는 개념입니다.
원하는 상태라 함은 관리자가 바라는 환경을 의미하고, 좀 더 구체적으로는 어떤 서비스가 얼마나 많이 서버에 떠있으면 좋을지?
몇 번 포트로 서비스하기를 원하는지 등을 나타냅니다.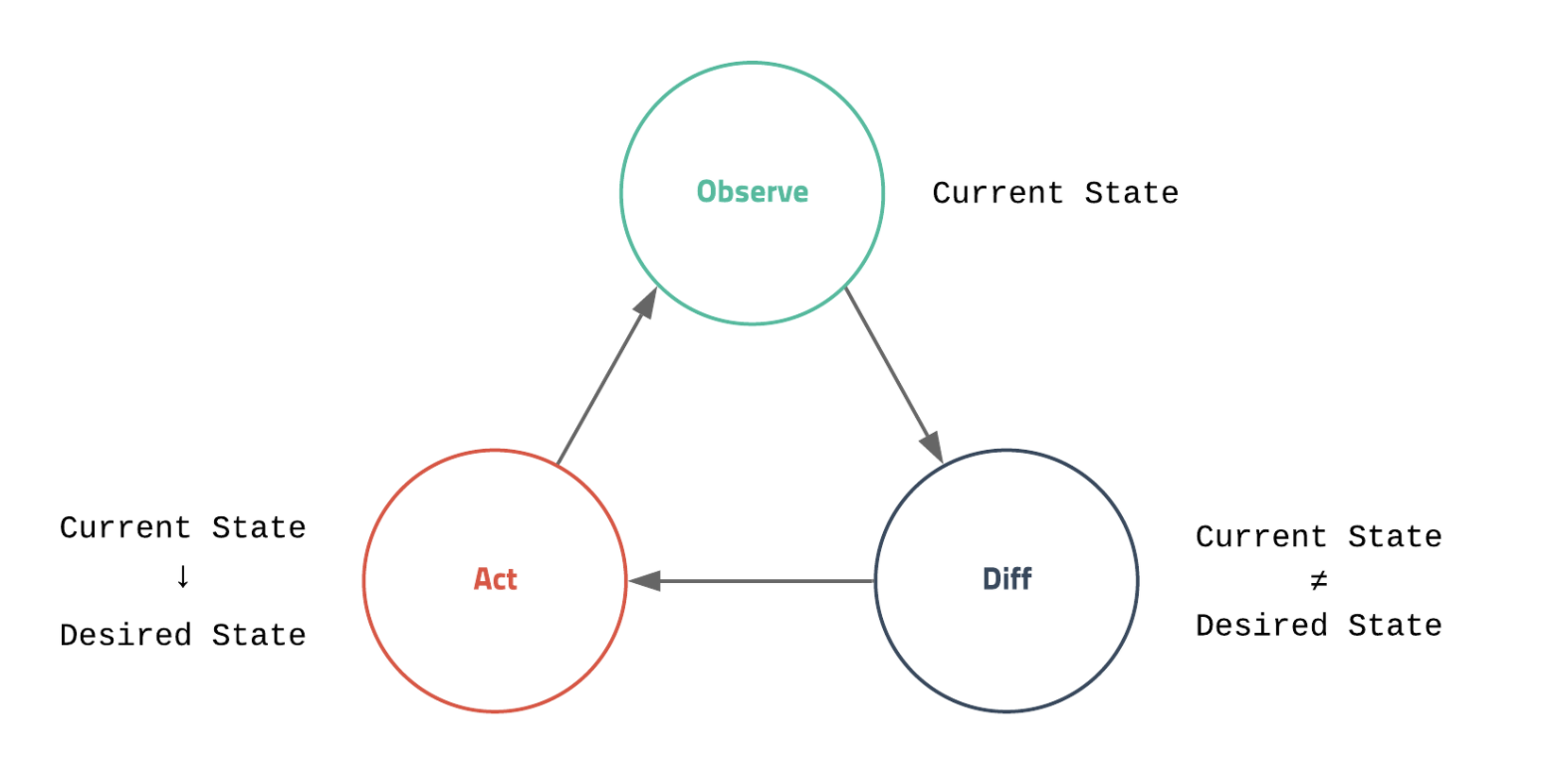
기본적으로 쿠버네티스틑 내가 원하는 상태(Desired State)와 현재 상태(Current State)를 비교하고, 만약 원하는 상태와 현재 상태가 다르다면 현재 상태를 원하는 상태로 변경하는 기능을 수행합니다.
즉, 쿠버네티스는 항상 우리가 원하는 상태로 현재 상태를 유지한다고 생각하면 될 것 같습니다.
그렇다면 이제부터는 어떻게 위와 같은 기능들이 수행되는지 알아보도록 하겠습니다.
Master
위에서 Master는 쿠버네티스의 설정 환경을 저장하고 전체 클러스터를 관리하는 역할을 맡고 있다고 설명하였습니다.
쿠버네티스는 MSA(Microservices Architecture) 형태로 설계되어 Master 내부에는 다음과 같이 나뉘어 있습니다.

위의 그림처럼 Master 내부에는 Api Server, Controller, Scheduler, etcd라는 것들이 존재합니다.
그렇다면 어떻게 동작하게 되는지 간단한 예시를 통해 알아보도록 하겠습니다.
Api Server
우리는 현재 아무것도 올라가 있지 않은 쿠버네티스 클러스터에 파이썬 애플리케이션을 올리는 요청을 보냈다고 가정을 하겠습니다.
요청을 보내게 되면 다음과 같이 진행되는 것을 알 수 있습니다.
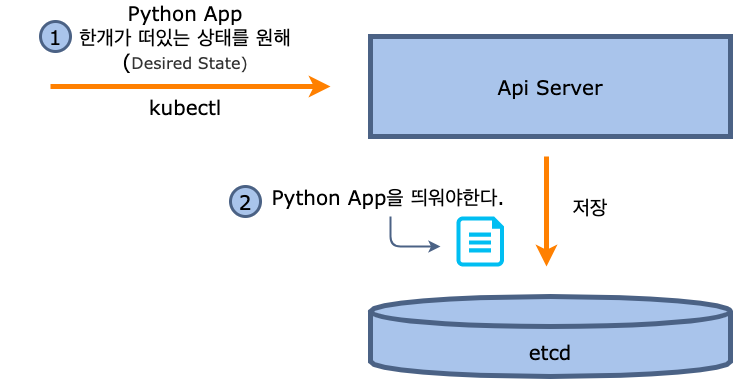
- 관리자는 Python App을 띄우도록 하는 Yaml파일을 작성하여 kubectl를 이용하여 쿠버네티스 클러스터에 요청을 하게 됩니다.
- 우리가 보낸 요청은 Api Server가 받게 되고 etcd라는 key, value저장소에 어떤 상태가 되어야 하는지를 저장합니다.
앞으로도 계속 나오겠지만 쿠버네티스의 모든 요청들은 Api Server을 통해서 수행되게 됩니다.
etcd는 key, value저장소입니다.
https://www.redhat.com/ko/topics/containers/what-is-etcd
쿠버네티스 클러스터의 모든 상태에 대한 정보를 저장하고 있습니다.
Controller
Controller는 위에서 말씀드렸던 Desired State를 유지하기 위해 지속적으로 변경사항이 있는지 확인하게 됩니다.
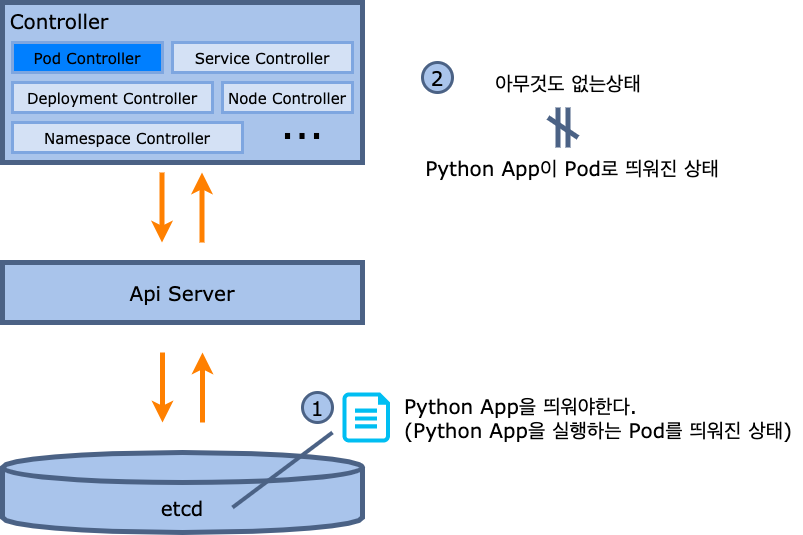
- Controller는 etcd에 저장되어있는 내용을 지속적으로 확인하고 있습니다.
- 위의 그림처럼 확인된 내용과 현재 상태가 다를 경우 위에서 설명한 Desired State를 유지하기 위한 조치를 취하게 됩니다.
Controller에는 각 워크로드들에 대한 컨트롤러가 존재하여 각각 모니터링을 하게 됩니다.
따라서 위의 그림에서처럼 Pod가 띄워져야 한다는 상태는 Pod Controller가 확인하여 현재 상태와 비교하게 되는 것입니다.Scheduler
Scheduler는 위의 Controller에서 새로운 워크로드(Pod)를 띄워야 한다고 했을 때 어떤 Node에 띄워야 하는지를 결정하게 됩니다.

위 그림처럼 새로운 서비스를 띄위기에 가장 효율적인 Node에 띄워지도록 지정하게 됩니다.
여기까지 각 Api Server, Controller, Scheduler, etcd를 통해서 Master에서는 쿠버네티스의 설정 환경을 저장하고 전체 클러스터를 관리하는 역할을 수행하게 됩니다.
Node
그럼 다음으로는 실제 워크로드들을 실행하게 되는 Node에 대해서 알아보도록 하겠습니다.

각 Node들에는 기본적으로 Kube-Proxy와 Kubelet 그리고 컨테이너 런타임이 존재합니다.
그리고 현재는 컨테이너 런타임으로 Docker를 사용하고 있는것을 그림을 통해 확인 할 수 있습니다.
Kubelet
Kubelet은 파드에서 컨테이너가 확실하게 동작하도록 관리합니다.
컨트롤 플레인(Master)에서 노드에 작업을 요청하는 경우 Kubelet이 이 작업을 실행합니다.
Kube-Proxy
노드로 들어오거는 네트워크 트래픽을 적절한 컨테이너로 라우팅하고, 로드밸런싱등 노드로 들어오고 나가는 네트워크 트래픽을 프록시하고, 노드와 마스터간의 네트워크 통신을 관리합니다.
위의 과정들을 다시한번 정리해 본다면 다음과 같습니다.

위의 그림을 통해서 Pod하나를 띄우는 과정에서도 쿠버네티스 내부의 여러개의 마이크로 서비스들이 각자의 역활을 수행하여 동작한다는것을 확인할 수 있습니다.
참고자료
- https://kubernetes.io/ko/docs/concepts/architecture/
- https://www.youtube.com/watch?v=rF4ucj1mxxw&t=38s
- https://www.youtube.com/watch?v=SNA1sSNlmy0&t=3s
- https://bcho.tistory.com/1258?category=731548
- https://www.redhat.com/ko/topics/containers/kubernetes-architecture
'kubernetes' 카테고리의 다른 글
쿠버네티스 | Pod 자원관리 (QoS) (2) 2021.07.25 쿠버네티스 | 패키지 매니저 Helm (0) 2021.07.22 쿠버네티스 | Pod 자원관리 (3) 2021.07.21 쿠버네티스 | 클러스터 설치 준비 (0) 2021.07.19 쿠버네티스 | 설치 (0) 2021.05.15